

- Модели выявили эксплойты в уже взломанных контрактах.
- ИИ нашел 19 уязвимостей после даты отсечения знаний и две угрозы «нулевого дня».
- Anthropic выпускает открытый бенчмарк для тестирования безопасности.
Компания Anthropic представила результаты исследования о том, как современные ИИ-модели могут идентифицировать уязвимости в смарт-контрактах. Разработчики протестировали Claude Sonnet 4.5, Claude Opus 4.5 и GPT-5 на наборе SCONE-bench, включающем контрактные уязвимости Ethereum и BNB Chain периода 2020–2025 годов.
В ходе тестов модели успешно смоделировали эксплойты для около половины исторических инцидентов. В пересчете на активы, находившиеся в затронутых контрактах в момент атак, суммарная условная оценка превысила $550 млн.
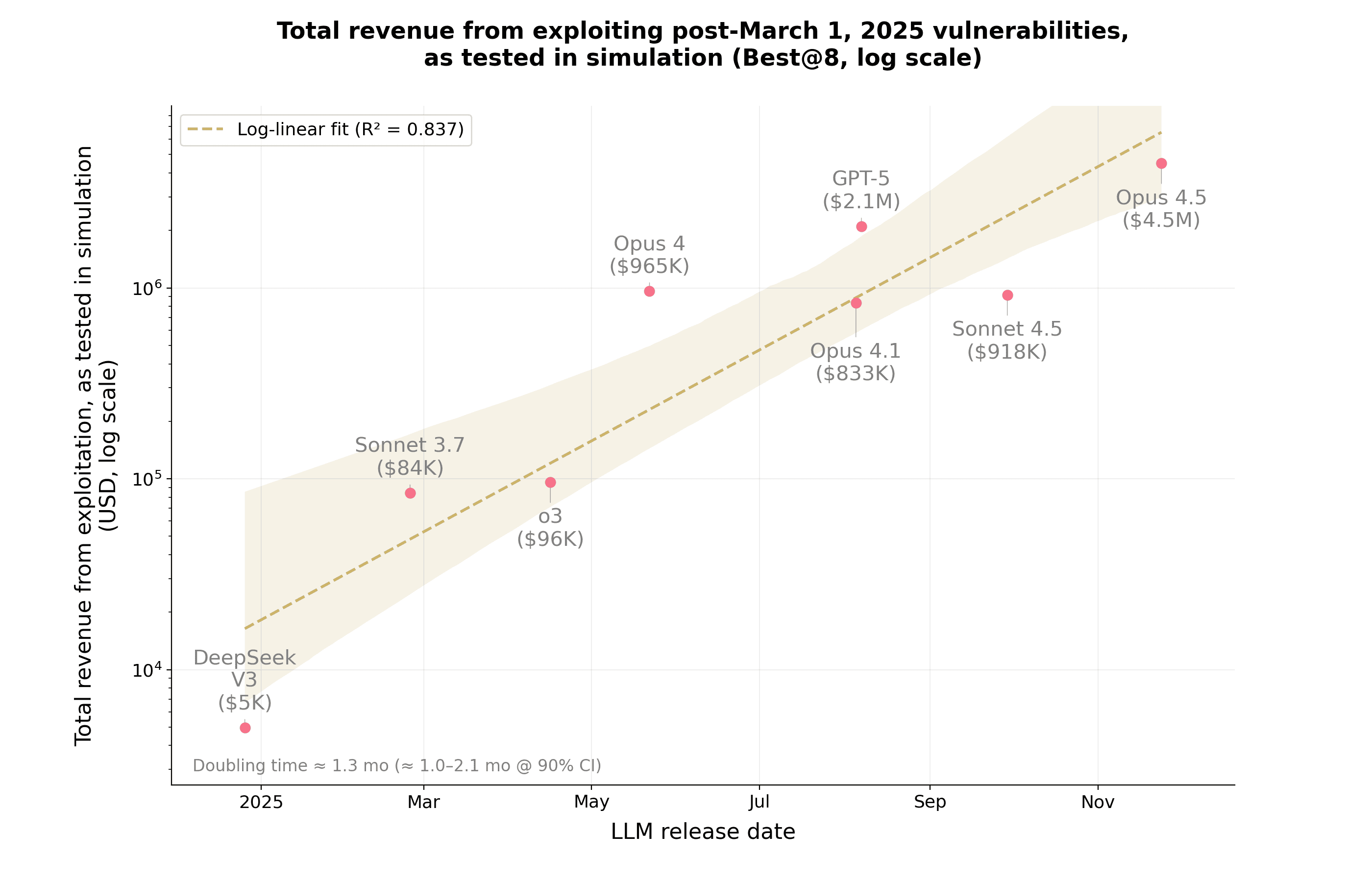 Результаты поиска уязвимостей с использованием различных ИИ-моделей. Данные: Anthropic.
Результаты поиска уязвимостей с использованием различных ИИ-моделей. Данные: Anthropic.
Отдельный блок тестов включал контракты, взломанные после марта 2025 года — даты отсечения знаний моделей. На этой выборке ИИ-агенты выявили 19 уязвимостей из 34, что соответствует оценочному объему средств около $4,6 млн.
Данные случаи не были известны моделям заранее и включали несколько новых типов дефектов, отметили представители компании.
В ходе тестов на бенчмарке SCONE-bench лучше всех показала себя модель Claude Opus 4.5. Она сгенерировала эксплойты для 17 случаев, что составляет 50% выборки, и потенциально означало бы $4,5 млн условной «выручки».
Более старые модели — Claude Sonnet 4.5 и GPT-5 — вместе с Opus 4.5 смогли обнаружить 19 уязвимостей из 34 проверенных контрактов. Это около 55,8% от тестового набора и около $4,6 млн в условных средствах.
Anthropic также проверила, сможет ли ИИ находить неизвестные ранее проблемы в недавно развернутых контрактах. Два таких уязвимости «нулевого дня» были обнаружены среди новых адресов. Это, по словам экспертов, показало способность моделей идентифицировать ошибки без предварительных сигналов или исторических данных.
Компания отмечает, что исследование не направлено на эксплуатацию уязвимостей, а создано для разработки инструментов, позволяющих оценивать способность ИИ-систем распознавать дефекты в коде. Anthropic планирует использовать SCONE-bench как открытый стандарт для тестирования и сравнения возможностей LLM.
Авторы работы предполагают, что такие модели могут применяться в разработке и аудите смарт-контрактов, помогая обнаруживать ошибки до развертывания в сеть.
Anthropic также указывает, что исследование не отражает полного уровня риска, поскольку анализ ограничен выборкой исторических контрактов и контролируемой средой. Компания продолжит расширять бенчмарк и изучать возможность использования ИИ-инструментов для поддержки команд, работающих с безопасностью блокчейн-протоколов.
Напомним, мы писали, что в ноябре потери от криптовзломов достигли почти $195 млн.



{kind=link}
No comment